How Kafka Connect + Streaming Databases Power Real-Time Decision Making (Part 2)
- Gang Tao

- Jul 12, 2023
- 3 min read
How to Connect Kafka Topics to Timeplus Streams
In my previous blog Part 1, we introduced why Kafka Connect and Streaming Databases are the best combination to support real-time data analytics in your organization. Now, let’s dig deeper into how you can do it with Timeplus.
As a real-time, streaming data analytics platform, the most important upstream data source for Timeplus is Apache Kafka. With our latest published Timeplus Kafka Sink Connector, Timeplus users can leverage the community of Kafka Connect and easily onboard different data sources supported by Kafka Connect into Timeplus.
Read on to learn how to connect your Kafka topic on Confluent Cloud to Timeplus Cloud to run real-time analytics.
First, create a test topic in your Confluent Cloud:
Choose Datagen Source with value format JSON and stock trade as the template.


This source connector will simulate stock trading information and generate the following data on the topic:
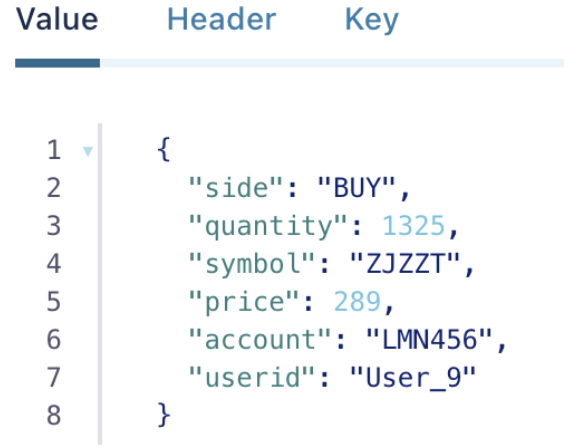
The data is now ready on the Kafka topic, so let’s create a Timeplus Sink Connector to move data from a Kafka Topic to Timeplus Cloud.
There are three different types of deployment mode for connectors: fully managed, self managed, and custom.

The Timeplus Sink Connector is available in self managed and custom modes.
Note: Confluent’s Custom Connectors are available on AWS in select regions. Support for additional regions and other cloud providers will be available in the future. refer to: https://www.confluent.io/press-release/new-confluent-features-make-it-easier-and-faster-to-connect-process-and-share-data/
Search for Timeplus in Connectors and click "Configure". In the Timeplus Kafka Sink Connector Page, click Download to download the connector package and use that package to create a custom connector running on Confluent Cloud.

On the Connectors page, click Add Connector and then chose Add Plugin

Input your connector plugin name and description and Connector class as "com.timeplus.kafkaconnect.TimeplusSinkConnector", upload your connector package by clicking Select connector archive.
Now, the customer plugin is ready to use. Go back to the Connectors page and click Add connector, filter by deployment type using "Custom", and you should see the Timeplus Sink there. Use it to create a Sink Connector.

When configure your Timeplus Sink on the second step , use the following JSON as your configuration:
{
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"timeplus.sink.address": "https://us.timeplus.cloud",
"timeplus.sink.apikey": "your-timeplus-api-key",
"timeplus.sink.createStream": "true",
"timeplus.sink.dataFormat": "json",
"timeplus.sink.stream": "stock_data_from_kafka",
"timeplus.sink.workspace": "your-timeplus-workspace-id",
"topics": "datagen",
"value.converter": "org.apache.kafka.connect.storage.StringConverter"
}Note that with the above configuration, the connector will try to create a stream with name "stock_data_from_kafka" in Timeplus using the JSON event, to infer all the fields names and types. You can also choose to create the stream by yourself i n Timeplus.
Additionally, when configuring the network, the Timeplus Cloud’s endpoints should be added:

For other configuration of Kafka credentials, such as sizing, just configure based on your use case.
It will take some time for Confluent to launch the connector. After the connector is running, the stream "stock_data_from_kafka" should have been created in your Timeplus workspace, and you run a stream query to analyze the data in real-time.

You can try the following SQL to get the total transaction values for each account in a one minute tumble window:
SELECT
window_start, account, side, sum(quantity * price) as value
FROM
tumble(stock_data_from_kafka, 1m)
WHERE
_tp_time > (now() - 10m)
GROUP BY
window_start, account, side
The query result will be returned in real-time as follows:
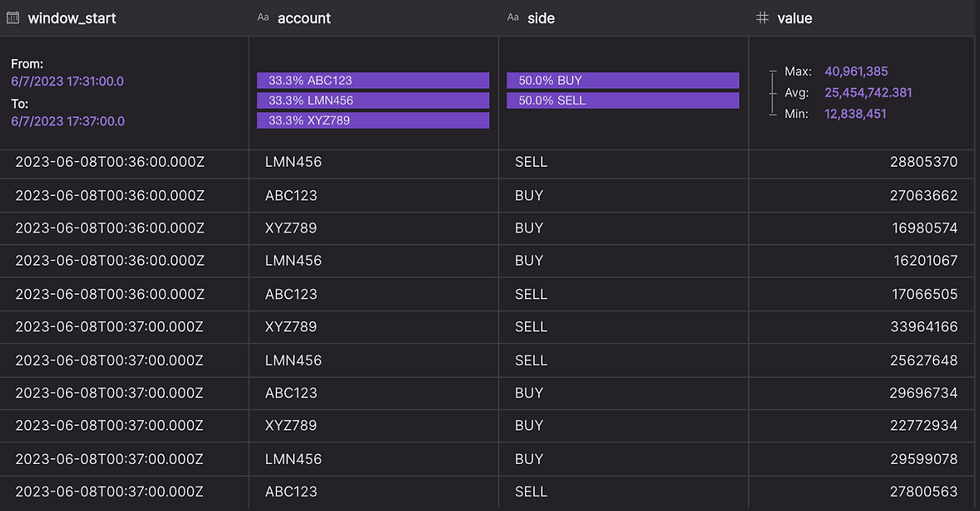
From generating the data to a real-time data analysis, It only took me a few minutes to connect the Confluent Kafka Topic to Timeplus Cloud. Cloud computing is helping data engineers save a lot of time managing complex data stacks.
Other than running the customer sink on Confluent Cloud, users can also choose to run self managed Kafka connect and connect to Confluent Cloud. Or, run it locally on any Kafka cluster – the source code is available here.
Summary
This in blog, we shared how easy it is to connect your real-time streaming data in Kafka topics using Timeplus’s Kafka Sink Connector. Timeplus' Kafka Sink Connector is available on Confluent Hub, which can be used to onboard your data in real-time and leverage these rich connectors eco-systems. Create your own workspace in Timeplus to unlock your real-time analysis with Kafka data.
